PyTorch Metric Learning¶
Google Colab Examples¶
See the examples folder for notebooks you can download or run on Google Colab.
Overview¶
This library contains 9 modules, each of which can be used independently within your existing codebase, or combined together for a complete train/test workflow.
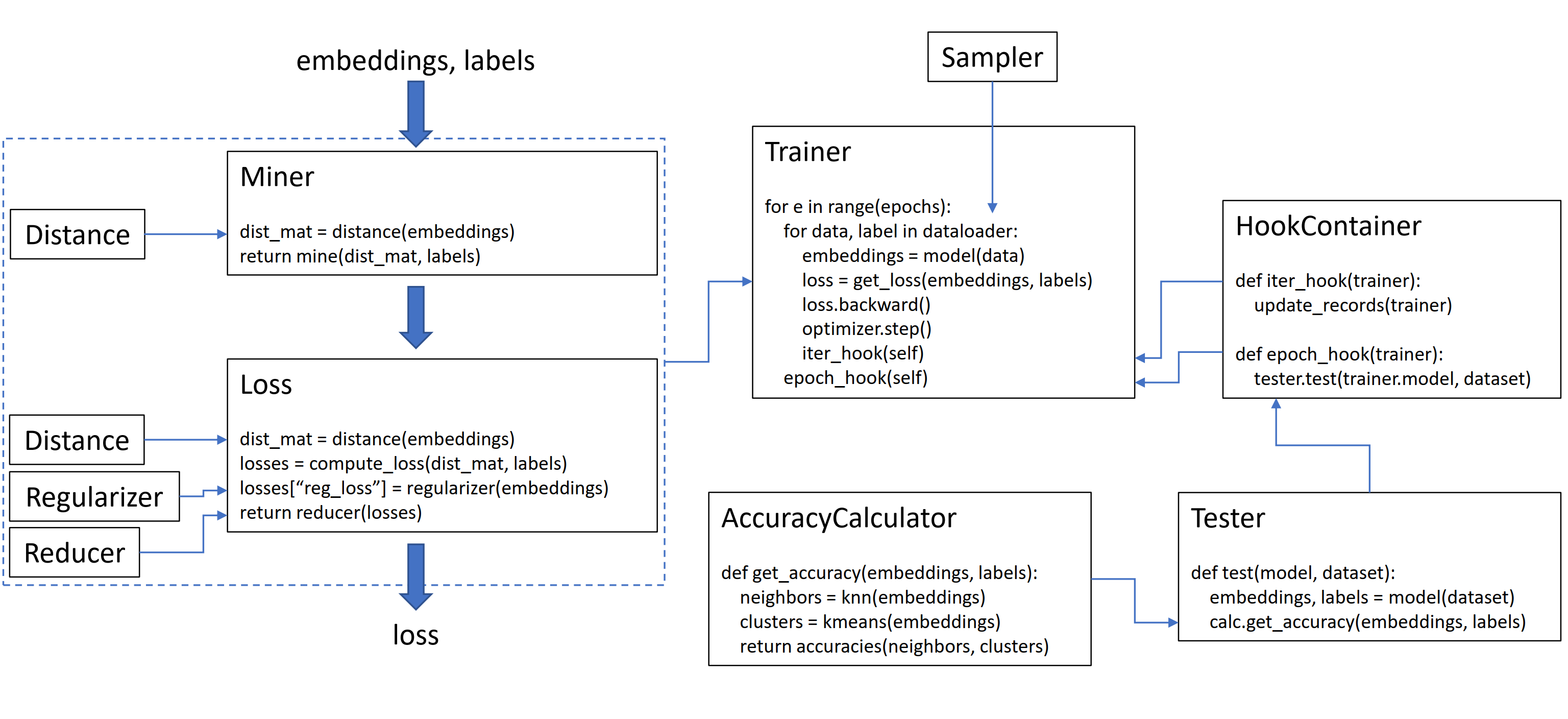
How loss functions work¶
Using losses and miners in your training loop¶
Let’s initialize a plain TripletMarginLoss:
from pytorch_metric_learning import losses
loss_func = losses.TripletMarginLoss()
To compute the loss in your training loop, pass in the embeddings computed by your model, and the corresponding labels. The embeddings should have size (N, embedding_size), and the labels should have size (N), where N is the batch size.
# your training loop
for i, (data, labels) in enumerate(dataloader):
optimizer.zero_grad()
embeddings = model(data)
loss = loss_func(embeddings, labels)
loss.backward()
optimizer.step()
The TripletMarginLoss computes all possible triplets within the batch, based on the labels you pass into it. Anchor-positive pairs are formed by embeddings that share the same label, and anchor-negative pairs are formed by embeddings that have different labels.
Sometimes it can help to add a mining function:
from pytorch_metric_learning import miners, losses
miner = miners.MultiSimilarityMiner()
loss_func = losses.TripletMarginLoss()
# your training loop
for i, (data, labels) in enumerate(dataloader):
optimizer.zero_grad()
embeddings = model(data)
hard_pairs = miner(embeddings, labels)
loss = loss_func(embeddings, labels, hard_pairs)
loss.backward()
optimizer.step()
Customizing loss functions¶
Loss functions can be customized using distances, reducers, and regularizers. In the diagram below, a miner finds the indices of hard pairs within a batch. These are used to index into the distance matrix, computed by the distance object. For this diagram, the loss function is pair-based, so it computes a loss per pair. In addition, a regularizer has been supplied, so a regularization loss is computed for each embedding in the batch. The per-pair and per-element losses are passed to the reducer, which (in this diagram) only keeps losses with a high value. The averages are computed for the high-valued pair and element losses, and are then added together to obtain the final loss.
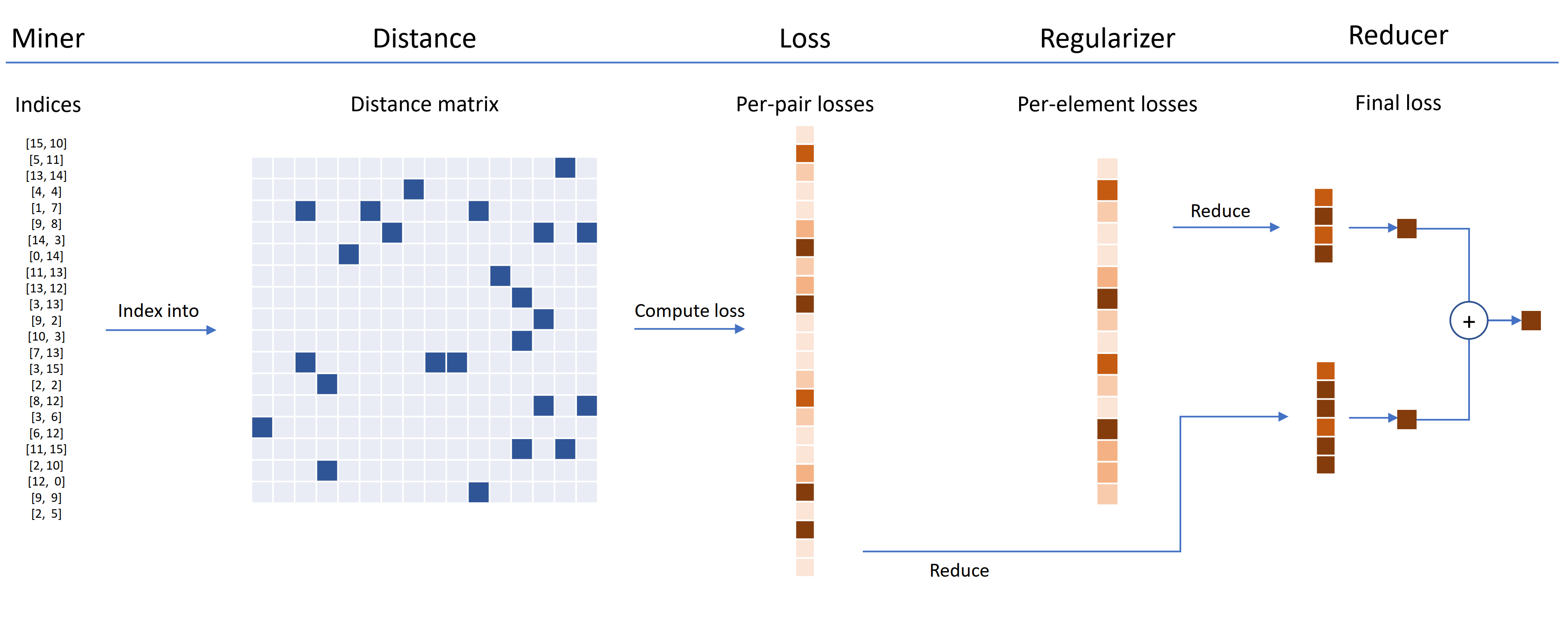
Now here's an example of a customized TripletMarginLoss:
from pytorch_metric_learning.distances import CosineSimilarity
from pytorch_metric_learning.reducers import ThresholdReducer
from pytorch_metric_learning.regularizers import LpRegularizer
from pytorch_metric_learning import losses
loss_func = losses.TripletMarginLoss(distance = CosineSimilarity(),
reducer = ThresholdReducer(high=0.3),
embedding_regularizer = LpRegularizer())
- The loss will be computed using cosine similarity instead of Euclidean distance.
- All triplet losses that are higher than 0.3 will be discarded.
- The embeddings will be L2 regularized.
Using loss functions for unsupervised / self-supervised learning¶
A SelfSupervisedLoss wrapper is provided for self-supervised learning:
from pytorch_metric_learning.losses import SelfSupervisedLoss
loss_func = SelfSupervisedLoss(TripletMarginLoss())
# your training for-loop
for i, data in enumerate(dataloader):
optimizer.zero_grad()
embeddings = your_model(data)
augmented = your_model(your_augmentation(data))
loss = loss_func(embeddings, augmented)
loss.backward()
optimizer.step()
If you're interested in MoCo-style self-supervision, take a look at the MoCo on CIFAR10 notebook. It uses CrossBatchMemory to implement the momentum encoder queue, which means you can use any tuple loss, and any tuple miner to extract hard samples from the queue.
Highlights of the rest of the library¶
- For a convenient way to train your model, take a look at the trainers.
- Want to test your model's accuracy on a dataset? Try the testers.
- To compute the accuracy of an embedding space directly, use AccuracyCalculator.
If you're short of time and want a complete train/test workflow, check out the example Google Colab notebooks.
Installation¶
Required PyTorch version¶
pytorch-metric-learning >= v0.9.90requirestorch >= 1.6pytorch-metric-learning < v0.9.90doesn't have a version requirement, but was tested withtorch >= 1.2
Pip¶
pip install pytorch-metric-learning
To get the latest dev version:
pip install pytorch-metric-learning --pre
To install on Windows:
pip install torch===1.6.0 torchvision===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install pytorch-metric-learning
To install with evaluation and logging capabilities (This will install the unofficial pypi version of faiss-gpu):
pip install pytorch-metric-learning[with-hooks]
To install with evaluation and logging capabilities (CPU) (This will install the unofficial pypi version of faiss-cpu):
pip install pytorch-metric-learning[with-hooks-cpu]
Conda¶
conda install -c conda-forge pytorch-metric-learning
To use the testing module, you'll need faiss, which can be installed via conda as well. See the installation instructions for faiss.